# 输入圆的半径输出周长和面积 import math as m r=eval(input('r=')) #input 输入的数据类型是字符,所以需要把它强制变为float或者int,或者用eval函数把他的''去掉,变成一个数据,而非字符串 print(type(r)) print('圆的周长是{:.2f} 圆的面积是{:.2f}'.format(2*m.pi*r,m.pi*r**2))
# 字符串 m1 = "my name is bond,James bond" print(m1) m2 = ''' A:What's your name? B:My name is bond,James bond.Very nice to see you! Comment:Salute to the 007,the famous character in a series of movies. ''' print(m2)
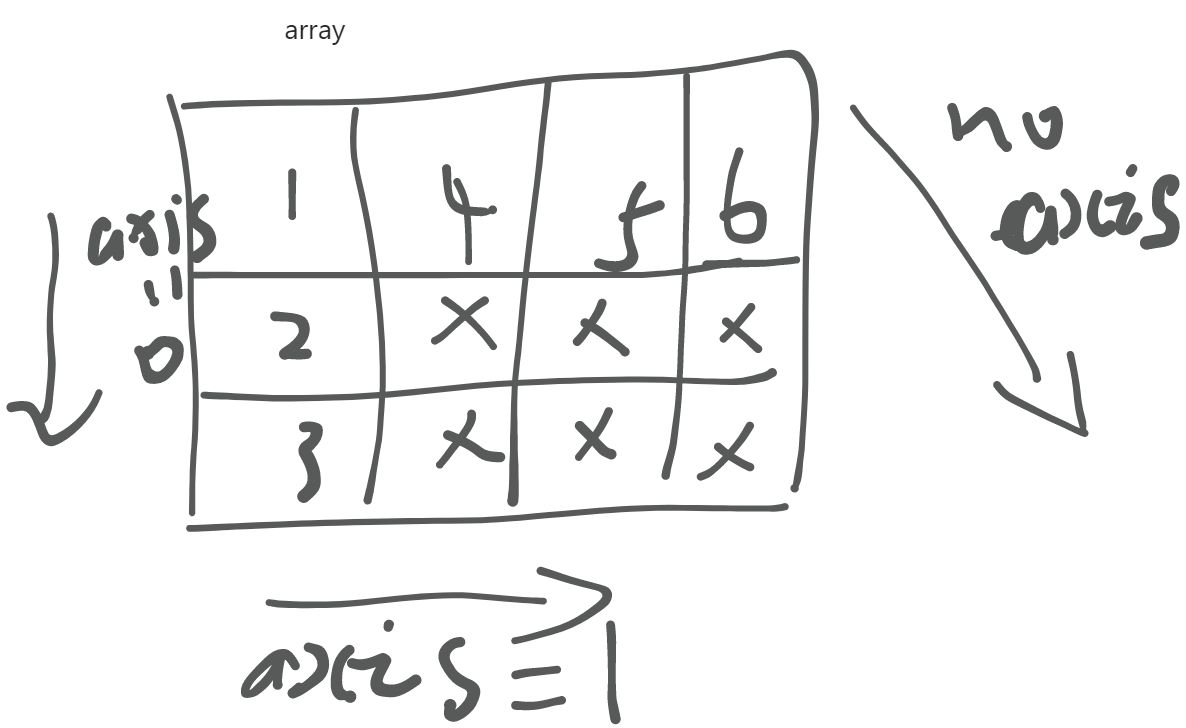
format():格式化函数
1 2 3 4 5 6 7 8 9 10 11 12 13
name='tl' book='bite of python ' # 使用索引代替位置,python索引从0开始 print('{0} wrote the {1}'.format(name,book)) # 直接使用大括号{}占用位置 print('{} wrote the {}'.format(name,book)) # 直接在format后面定义变量,但是前面的变量用大括号括起来 print('{name} wrote the {book}'.format(name='tlin',book='python')) # format还可以进行保留小数点后几位,关键在前面的:.nf print('{:.2f}'.format(1.0/3)) #保留两位 print('{:.5f}'.format(1.0/3)) #保留五位 # format还可以进行补充字符长度操作 print('{:-^8}'.format('hello')) # ^声明进行补充,用-补充8位
# 判断输入的边长能否构成三角形,如果能则计算出三角形的周长和面积 import math as mt a=float(input('a=')) b=float(input('b=')) c=float(input('c=')) if a+b>c and a+c>b and b+c>a: print('三条边%f,%f,%f可以构成三角形'%(a,b,c)) p=(a+b+c)/2 print('三角形周长为%f'%(p*2)) s=mt.sqrt(p*(p-a)*(p-b)*(p-c)) print('三角形的面积为%f'%(s)) else: print('三条边无法构成三角形')
# 猜数字游戏 import random as rd answer=rd.randint(1, 100) #randint(a,b)是 a=<x<=b counter=0 whileTrue: number=int(input('your choice is :')) counter+=1 if number>answer: print('小一点') elif number<answer: print('大一点') else: print('you are right') break print('you have guessed %d results'%(counter)) if counter>7: print('you need to eat more food,hahaha') else: print('you are so smart,you have mastered the secret of playing this game')
1 2 3 4 5
# 输出九九乘法表 for i inrange(1,10): for j inrange(1,i+1): print('%d*%d=%d'%(i,j,i*j),end='\t') print()
下面有三个小练习:
1 2 3 4 5 6 7 8 9
number=int(input('number=')) counter=0 for i inrange(1,number+1): if number%i==0: counter+=1 if counter<=2and number!=1: print('%d is a prime number'%(number)) else: print('%d isn\'t a prime number')
1 2 3 4 5 6 7 8 9
if a>=b: a,b=a,b else: a,b=b,a for i inrange(a,1,-1): if a%i==0and b%i==0: max=i print('The greatest common divisor of %d and %d is %d '%(a,b,max)) print('The least common multiple of %d and %d is %d '%(a,b,a*b/max))
# * # ** # *** # **** # ***** # * # *** # ***** # ******* # ********* for i inrange(5,0,-1): for j inrange(1,i): print(' ',end='') for j inrange(5,i-1,-1): print('*',end='') print()
for i inrange(5,0,-1): for j inrange(5,i-1,-1): print('*',end='') print() for i inrange(5,0,-1): for j inrange(1,i): print(' ',end='') for j inrange(5,i-1,-1): print('*',end='') for j inrange(5,i,-1): print('*',end='') print()
循环经典案例
1 2 3 4 5 6 7 8
# 说明:水仙花数也被称为超完全数字不变数、自恋数、自幂数、阿姆斯特朗数,它是一个3位数, # 该数字每个位上数字的立方之和正好等于它本身,例如:$1^3 + 5^3+ 3^3=153$。 for i inrange(100,1000): a=i%10 b=i//10%10 c=(i-a-b*10)/100 if a**3+b**3+c**3==i: print(i)
1 2 3 4 5 6 7
# 正整数的反转 num=int(input('number is :')) reversed_number=0 while num>0: reversed_number=reversed_number*10+num%10 num//=10 print(reversed_number)
1 2 3 4 5 6 7 8 9 10 11
# 百钱白鸡问题 # 说明:百钱百鸡是我国古代数学家张丘建在《算经》一书中提出的数学问题: # 鸡翁一值钱五,鸡母一值钱三,鸡雏三值钱一。百钱买百鸡,问鸡翁、鸡母、鸡雏各几何? # 翻译成现代文是:公鸡5元一只,母鸡3元一只,小鸡1元三只,用100块钱买一百只鸡, # 问公鸡、母鸡、小鸡各有多少只? # 假设公鸡有x,母鸡有y,小鸡有z,满足数量关系和钱数关系 for x inrange(0,21): for y inrange(0,34): for z inrange(0,101): if x+y+z==100and5*x+3*y+z/3==100: print(x,y,z)
# CRAPS赌博游戏 from random import randint # 游戏初始化资金 money=int(input('your property is ')) start=True while start: start=False # 设置赌资 debt=int(input('your debt chosen is : ')) if debt>money or debt<0: break # 游戏开始 first=randint(1,6)+randint(1, 6) if first==7or first==11: print('you win') money+=debt elif first==2or first==3or first==12: print('the makers win,you lost') money-=debt else: go_on=True while go_on: go_on=False num=randint(1,6)+randint(1, 6) if num==7: print('you lost') money-=debt elif num==first: print('you win') money+=debt else: go_on=True print('your property is now %d'%(money)) a=int(input('please choose to go on(1) or give up(0) :')) if a==1and money!=0: start=True elif a==0: start=False print('you can control yourself,you are worth to be learned by me,the maker of the game') else: start=False print('I am sorry to tell you that you have lost yourself, be wise')
循环习题
1 2 3 4 5 6 7 8
# 输出一百以内的素数 for i inrange(1,100): counter=0 for j inrange(1,i+1): if i%j==0: counter+=1 if counter <= 2and i != 1: print(i)
1 2 3 4 5 6 7 8 9 10
# 找出10000以内的完美数。 # 说明:完美数又称为完全数或完备数,它的所有的真因子(即除了自身以外的因子)的和(即因子函数)恰好等于它本身。 # 例如:6($6=1+2+3$)和28($28=1+2+4+7+14$)就是完美数。完美数有很多神奇的特性,有兴趣的可以自行了解。 for i inrange(2,10000): sum=0 for j inrange(1,i): if i%j==0: sum+=j ifsum==i: print(i)
defadd(*a): #定义a是可变参数 sum=0 for i in a: sum+=i returnsum print(add(1,2,3)) print(add(2,3))
用模块管理函数:
由于python没有函数重载的概念,对于同名的函数,先后定义,后面函数会覆盖前面的函数,因此在不同的模块(一个文件就是一个模块,module)使用import载入该函数,例如在module1.py中定义foo函数,在module2.py中定义foo函数,from module1 import foo as m1和from module2 import foo as m2,分别执行是不会发生冲突的,或者直接import module1 as m1,再用m1.foo(),用点函数运算操作
defgcd(x, y): # 求最大公因数 if x < y: x, y = y, x factor = 0 for i inrange(x, 0, -1): if x % i == 0and y % i == 0: factor = i break return factor
defscm(x, y): # 求最小公倍数 a = gcd(x, y) return x*y/a
defhws(num): # 判断是否是回文数 temp=num reversed_num = 0 while temp > 0: reversed_num = reversed_num*10+temp % 10 temp //= 10 return num==reversed_num defis_prime(num): # 判断是否质数 counter=0 if num==1: returnFalse else: # 判断因子个数 for i inrange(1,num+1): if num%i==0: counter+=1 if counter>2: returnFalse else: returnTrue if __name__=='__main__': num=int(input('the number is ')) if is_prime(num) and hws(num): print('%d is a prime number and a palindromic number'%(num)) else: print('it isn\'t a prime number and a palindromic number' )
字符串:把零个或者多个字符用单引号或者双引号括起来形成的,即形成了字符串,在字符串的输出中,可以利用转义符,+某些字母,\n,\t等等,\也可以加一些unicode字符来产生中文等,https://www.ifreesite.com/unicode-ascii-ansi.htm这个链接可以进行中文和Unicode字符互换,之外,若不想要\进行转义,可在字符串的最前端加上r或者R,字符串进行运算符操作,+可进行字符串的拼接,而*可以进行字符串的重复,*n即是重复n次,用in or not in 来进行bool运算,以及用[],或者[:]进行切片操作
1 2 3 4 5 6 7 8
a='hello' b='world' print(a+b) #字符串的拼接 print(a*2+b*8) #字符串的重复 print('he'in a) #字符串的属于与不属于关系 print('a'notin a) print(a[:3]) print(a[::2])
import sys f=[x for x inrange(101)] #这是列表的生成式语法 print(f) f=[x+y for x in'ABCDE'for y in'12345'] print(f) f=[x**2for x inrange(11)] print(sys.getsizeof(f)) #184 print(f) f=(x**2for x inrange(11)) #这是一个生成器,用小括号括起来,占用更少的内存资源 print(sys.getsizeof(f)) #112 print(f) for i in f: print(i)
1 2 3 4 5 6 7 8
# 产生生成器函数的另一种方法,用yield关键字代替return进行声明 deffb(n): a,b=0,1 for _ inrange(n): a,b=b,a+b yield a #这里用yield代替了return for i in fb(20): print(i)
defmain(): import os import time content = '北京欢迎你,你的到来是我莫大的荣幸-------' go_on = True while go_on: # 清理屏幕上的输出 os.system('cls') print(content) # 延迟0.2s time.sleep(0.2) content = content[1:]+content[0] pass
if __name__ == '__main__': main()
设计一个函数产生指定长度的验证码,验证码由大小写字母和数字构成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
defgenerate_coed(n): ''' Parameters ---------- n : TYPE, optional DESCRIPTION. The default is 4. Returns 一个由数字和大小写字母组成验证码 ------- None. ''' import random choice='0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' num=len(choice) code='' for i inrange(n): code+=choice[random.randint(1,num)] return code print(generate_coed(5))
defget_max_secmax(list): ''' 返回列表中最大和第二大的值 Parameters ---------- list : TYPE :this is a list,and all of elements are numbers DESCRIPTION. Returns the greatest and second greatest numbers ------- None. ''' num=len(list) largest=list[0] for i inrange(num): iflist[i]>=largest: largest=list[i] list2=list[:] list2.remove(largest) sec_largest=list2[0] for i inrange(len(list2)): iflist[i]>=sec_largest: sec_largest=list[i] return largest,sec_largest pass get_max_secmax([1,5,7,911,1500])
计算指定的年月日是这一年的第几天
1 2 3 4 5 6 7 8 9 10 11 12
defis_leap_year(year): return year%100!=0and year%4==0or year %100==0and year %400==0 pass defreturn_day(year,month,day): days=[[31,28,31,30,31,30,31,31,30,31,30,31],[31,29,31,30,31,30,31,31,30,31,30,31]] year_days=days[1] if is_leap_year else days[2] sum=0 for i inrange(month-1): sum+=year_days[i] print(f'这是{year}的第{sum+day}天') return_day(2020,5,25) return_day(2020,1,1)
杨辉三角
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# 实现杨辉三角 defyanghui(n): lt=[[]]*n for row inrange(n): lt[row]=[None]*(row+1) for col inrange(len(lt[row])): if col==0or col==row: lt[row][col]=1 else: lt[row][col]=lt[row-1][col-1]+lt[row-1][col] for i inrange(n): x=str(lt[i]) print(x.center(n*10)) pass
# create a file file=open('file1.txt','w') file.write('my name is tanlin.') file.write('what\'s your name?') file.close()
1 2 3 4 5 6 7 8 9 10 11
# read a file file = open('file1.txt','r') #注意,这里的mode是r #show whole efile print(file.read()) #show first ten characterrs print(file.read(10)) #view by line print(file.readline()) #view all by line print(file.readlines()) file.close()
1 2 3 4
file=open('file1.txt','r+') for i in file: print(i) file.close()
注:在进行完文件的操作后,要进行文件的关闭,file.close() ,由于很容易打开文件之后忘记关闭文件,所以最好用with方法,即with open(‘filename’,‘mode’) as f:
1 2 3 4 5 6
file = open('file1.txt', 'a',encoding='UTF-8') file.write('\nI am back again. \n') file.write('Do you miss me?\n') file.close() file = open('file1.txt', 'r+',encoding='UTF-8') print(file.read())
def__init__(self, name): self.name = name print('initializing {}'.format(self.name)) robot.population += 1
defdie(self): print(f'{self.name} is being destroyed') robot.population -= 1 if robot.population == 0: print(f'{self.name} is the last robot') else: print(f'there are still {robot.population } robots')
defsay_hi(self): print('greetings, my master call me {}'.format(self.name))
@classmethod defhow_many(cls): print(f'we have {cls.population } robots')